本文共 15730 字,大约阅读时间需要 52 分钟。
转自:
原文地址
方法之三:以为基点,触类旁通
结构化程序设计思想认为:程序 =数据结构 +。数据结构体现了整个系统的构架,所以数据结构通常都是代码分析的很好的着手点,对内核分析尤其如此。比如,把进程控制块结构分析清楚 了,就对进程有了基本的把握;再比如,把页目录结构和页表结构弄懂了,两级虚存映射和内存管理也就掌握得差不多了。为了体现循序渐进的思想,在这我就以 Linux对中断机制的处理来介绍这种方法。
首先,必须指出的是:在此处,中断指广义的中断概义,它指所有通过idt进行的控制转移的机制和处理;它覆盖以下几个常用的概义:中断、异常、可屏蔽中断、不可屏蔽中断、硬中断、软中断 … … …
I、硬件提供的中断机制和约定
一.中断向量寻址:
硬件提供可供256个服务程序中断进入的入口,即中断向量;
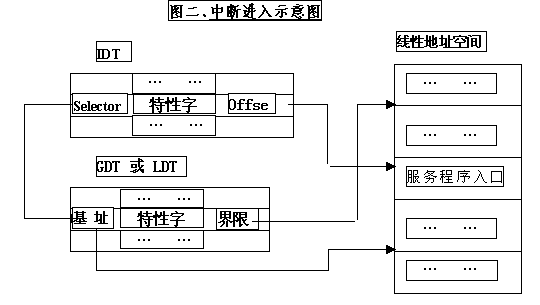
中断向量在保护模式下的实现机制是中断描述符表idt,idt的位置由idtr确定,idtr是个48位的寄存器,高32位是idt的基址,低16位为idt的界限(通常为2k=256*8);
idt中包含256个中断描述符,对应256个中断向量;每个中断描述符8位,其结构如图一:

中断进入过程如图二所示。
当中断是由低特权级转到高特权级(即当前特权级CPL>DPL)时,将进行堆栈的转移;内层堆栈的选择由当前tss的相应字段确定,而且内层堆栈将依次被压入如下数据:外层SS,外层ESP,EFLAGS,外层CS,外层EIP; 中断返回过程为一逆过程;
二.异常处理机制:
Intel公司保留0-31号中断向量用来处理异常事件:当产生一个异常时,处理机就会自动把控制转移到相应的处理程序的入口,异常的处理程序由提供,中断向量和异常事件对应如表一:
表一、中断向量和异常事件对应表
| 中断向量号 | 异常事件 | Linux的处理程序 |
| 0 | 除法错误 | Divide_error |
| 1 | 调试异常 | Debug |
| 2 | NMI中断 | Nmi |
| 3 | 单字节,int 3 | Int3 |
| 4 | 溢出 | Overflow |
| 5 | 边界监测中断 | Bounds |
| 6 | 无效操作码 | Invalid_op |
| 7 | 设备不可用 | Device_not_available |
| 8 | 双重故障 | Double_fault |
| 9 | 协处理器段溢出 | Coprocessor_segment_overrun |
| 10 | 无效TSS | Incalid_tss |
| 11 | 缺段中断 | Segment_not_present |
| 12 | 堆栈异常 | Stack_segment |
| 13 | 一般保护异常 | General_protection |
| 14 | 页异常 | Page_fault |
| 15 | Spurious_interrupt_bug | |
| 16 | 协处理器出错 | Coprocessor_error |
| 17 | 对齐检查中断 | Alignment_check |
三.可编程中断控制器8259A:
为更好的处理外部设备,x86微机提供了两片可编程中断控制器,用来辅助cpu接受外部的中断信号;对于中断,cpu只提供两个外接引线:NMI和INTR;
NMI只能通过端口操作来屏蔽,它通常用于:电源掉电和物理存储器奇偶验错;
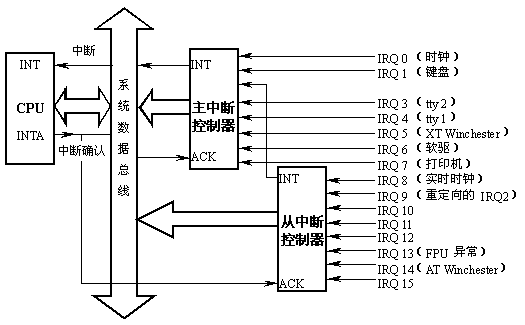
INTR可通过直接设置中断屏蔽位来屏蔽,它可用来接受外部中断信号,但只有一个引线,不够用;所以它通过外接两片级链了的8259A,以接受更多的外部中断信号。8259A主要完成这样一些任务:
-
- 中断优先级排队管理,
- 接受外部中断请求
- 向cpu提供中断类型号
外部设备产生的中断信号在IRQ(中断请求)管脚上首先由中断控制器处理。中断控制器可 以响应多个中断输入,它的输出连接到 CPU 的 INT 管脚,信号可通过INT 管脚,通知处理器产生了中断。如果 CPU 这时可以处理中断,CPU 会通过 INTA(中断确认)管脚上的信号通知中断控制器已接受中断,这时,中断控制器可将一个 8 位数据放置在数据总线上,这一 8 位数据也称为中断向量号,CPU 依据中断向量号和中断描述符表(IDT)中的信息自动调用相应的中断服务程序。图三中,两个中断控制器级联了起来,从属中断控制器的输出连接到了主中断控 制器的第 3 个中断信号输入,这样,该系统可处理的外部中断数量最多可达 15 个,图的右边是 i386 PC 中各中断输入管脚的一般分配。可通过对8259A的初始化,使这15个外接引脚对应256个中断向量的任何15个连续的向量;由于intel公司保留0- 31号中断向量用来处理异常事件(而默认情况下,IBM bios把硬中断设在0x08-0x0f),所以,硬中断必须设在31以后,linux则在实模式下初始化时把其设在0x20-0x2F,对此下面还将具 体说明。
图三、i386 PC 可编程中断控制器8259A级链示意图
II、Linux的中断处理
硬件中断机制提供了256个入口,即idt中包含的256个中断描述符(对应256个中断向量)。
而0-31号中断向量被intel公司保留用来处理异常事件,不能另作它用。对这 0-31号中断向量,操作系统只需提供异常的处理程序,当产生一个异常时,处理机就会自动把控制转移到相应的处理程序的入口,运行相应的处理程序;而事实 上,对于这32个处理异常的中断向量,此版本(2.2.5)的 Linux只提供了0-17号中断向量的处理程序,其对应处理程序参见表一、中断向量和异常事件对应表;也就是说,17-31号中断向量是空着未用的。
既然0-31号中断向量已被保留,那么,就是剩下32-255共224个中断向量可用。 这224个中断向量又是怎么分配的呢?在此版本(2.2.5)的Linux中,除了0x80 (SYSCALL_VECTOR)用作系统调用总入口之外,其他都用在外部硬件中断源上,其中包括可编程中断控制器8259A的15个irq;事实上,当 没有定义CONFIG_X86_IO_APIC时,其他223(除0x80外)个中断向量,只利用了从32号开始的15个,其它208个空着未用。
这些中断服务程序入口的设置将在下面有详细说明。
一.相关数据结构
- 中断描述符表idt: 也就是中断向量表,相当如一个数组,保存着各中断服务例程的入口。(详细描述参见图一、中断描述符格式)
- 与硬中断相关数据结构:
与硬中断相关数据结构主要有三个:
一:定义在/arch/i386/kernel/irq.h中的
struct hw_interrupt_type {
const char * typename;
void (*startup)(unsigned int irq);
void (*shutdown)(unsigned int irq);
void (*handle)(unsigned int irq, struct pt_regs * regs);
void (*enable)(unsigned int irq);
void (*disable)(unsigned int irq);
};
二:定义在/arch/i386/kernel/irq.h中的
typedef struct {
unsigned int status; /* IRQ status - IRQ_INPROGRESS, IRQ_DISABLED */
struct hw_interrupt_type *handler; /* handle/enable/disable functions */
struct irqaction *action; /* IRQ action list */
unsigned int depth; /* Disable depth for nested irq disables */
} irq_desc_t;
三:定义在include/linux/ interrupt.h中的
struct irqaction {
void (*handler)(int, void *, struct pt_regs *);
unsigned long flags;
unsigned long mask;
const char *name;
void *dev_id;
struct irqaction *next;
};
三者关系如下:
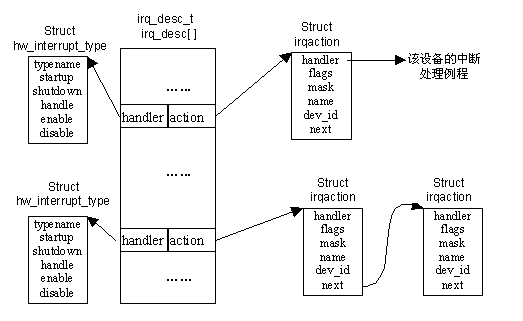
图四、与硬中断相关的几个数据结构各关系
各结构成员详述如下:
-
- struct irqaction结构,它包含了内核接收到特定IRQ之后应该采取的操作,其成员如下:
- handler:是一指向某个函数的指针。该函数就是所在结构对相应中断的处理函数。
- flags:取值只有SA_INTERRUPT(中断可嵌套),SA_SAMPLE_RANDOM(这个中断是源于物理随机性的),和SA_SHIRQ(这个IRQ和其它struct irqaction共享)。
- mask:在x86或者体系结构无关的代码中不会使用(除非将其设置为0);只有在SPARC64的移植版本中要跟踪有关软盘的信息时才会使用它。
- name:产生中断的硬件设备的名字。因为不止一个硬件可以共享一个IRQ。
- dev_id:标识硬件类型的一个唯一的ID。Linux支持的所有硬件设备的每一种类型,都有一个由制造厂商定义的在此成员中记录的设备ID。
- next:如果IRQ是共享的,那么这就是指向队列中下一个struct irqaction结构的指针。通常情况下,IRQ不是共享的,因此这个成员就为空。
-
- struct hw_interrupt_type结构,它是一个抽象的中断控制器。这包含一系列的指向函数的指针,这些函数处理控制器特有的操作:
- typename:控制器的名字。
- startup:允许从给定的控制器的IRQ所产生的事件。
- shutdown:禁止从给定的控制器的IRQ所产生的事件。
- handle:根据提供给该函数的IRQ,处理唯一的中断。
- enable和disable:这两个函数基本上和startup和shutdown相同;
- 另外一个数据结构是irq_desc_t,它具有如下成员:
- status:一个整数。代表IRQ的状态:IRQ是否被禁止了,有关IRQ的设备当前是否正被自动检测,等等。
- handler:指向hw_interrupt_type的指针。
- action:指向irqaction结构组成的队列的头。正常情况下每个IRQ只有一个操作,因此链接列表的正常长度是1(或者0)。但是,如果IRQ被两个或者多个设备所共享,那么这个队列中就有多个操作。
- depth:irq_desc_t的当前用户的个数。主要是用来保证在中断处理过程中IRQ不会被禁止。
- irq_desc是irq_desc_t 类型的数组。对于每一个IRQ都有一个数组入口,即数组把每一个IRQ映射到和它相关的处理程序和irq_desc_t中的其它信息。
- 与Bottom_half相关的数据结构:
图五、底半处理数据结构示意图
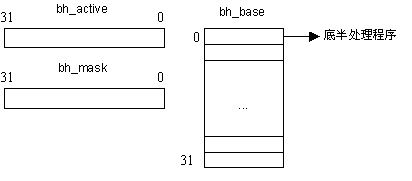
- bh_mask_count:计数器。对每个enable/disable请求嵌套对进行计数。这些请求通过调用enable_bh和 disable_bh实现。每个禁止请求都增加计数器;每个使能请求都减小计数器。当计数器达到0时,所有未完成的禁止语句都已经被使能语句所匹配了,因 此下半部分最终被重新使能。(定义在kernel/softirq.c中)
- bh_mask和bh_active:它们共同决定下半部分是否运行。它们两个都有32位,而每一个下半部分都占用一位。当一个上半部 分(或者一些其它代码)决定其下半部分需要运行时,就通过设置bh_active中的一位来标记下半部分。不管是否做这样的标记,下半部分都可以通过清空 bh_mask中的相关位来使之失效。因此,对bh_mask和bh_active进行位AND运算就能够表明应该运行哪一个下半部分。特别是如果位与运 算的结果是0,就没有下半部分需要运行。
- bh_base:是一组简单的指向下半部分处理函数的指针。
bh_base代表的指针数组中可包含 32 个不同的底半处理程序。bh_mask 和 bh_active 的数据位分别代表对应的底半处理过程是否安装和激活。如果 bh_mask 的第 N 位为 1,则说明 bh_base 数组的第 N 个元素包含某个底半处理过程的地址;如果 bh_active 的第 N 位为 1,则说明必须由调度程序在适当的时候调用第 N 个底半处理过程。
二. 向量的设置和相关数据的初始化:
-
- 在实模式下的初始化过程中,通过对中断控制器8259A-1,9259A-2重新编程,把硬中断设到0x20-0x2F。即把IRQ0& #0;IRQ15分别与0x20-0x2F号中断向量对应起来;当对应的IRQ发生了时,处理机就会通过相应的中断向量,把控制转到对应的中断服务例 程。(源码在Arch/i386/boot/setup.S文件中;相关内容可参见 实模式下的初始化 部分)
- 在保护模式下的初始化过程中,设置并初始化idt,共256个入口,服务程序均为ignore_int, 该服务程序仅打印“Unknown interruptn”。(源码参见Arch/i386/KERNEL/head.S文件;相关内容可参见 保护模式下的初始化 部分)
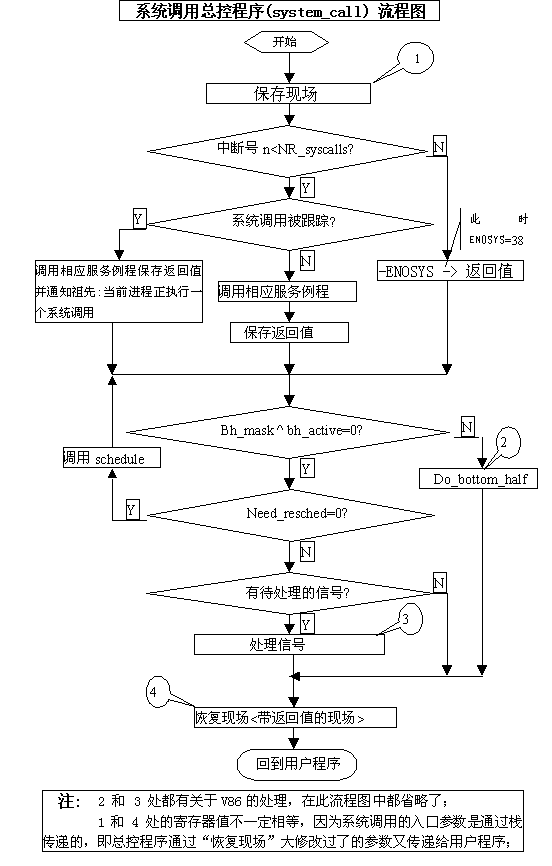
- 在系统初始化完成后运行的第一个内核程序asmlinkage void __init start_kernel(void) (源码在文件init/main.c中) 中,通过调用void __init trap_init(void)函数,把各自陷和中断服务程序的入口地址设置到 idt 表中,即将表一中对应的处理程序入口设置到相应的中断向量表项中;在此版本(2.2.5)的Linux只设置0-17号中断向量。(trap_init (void)函数定义在arch/i386/kernel/traps.c 中; 相关内容可参见 详解系统调用 部分)
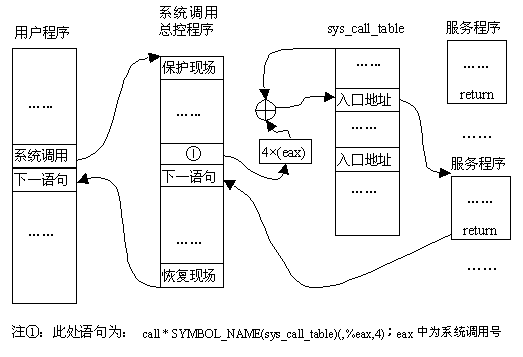
- 在同一个函数void __init trap_init(void)中,通过调用函数set_system_gate(SYSCALL_VECTOR,&system_call); 把系统调用总控程序的入口挂在中断0x80上。其中SYSCALL_VECTOR是定义在 linux/arch/i386/kernel/irq.h中的一个常量0x80; 而 system_call 即为中断总控程序的入口地址;中断总控程序用汇编语言定义在arch/i386/kernel/entry.S中。(相关内容可参见 详解系统调用 部分)
- 在系统初始化完成后运行的第一个内核程序asmlinkage void __init start_kernel(void) (源码在文件init/main.c中) 中,通过调用void init_IRQ(void)函数,把地址标号interrupt[i](i从1-223)设置到 idt 表中的的32-255号中断向量(0x80除外),外部硬件IRQ的触发,将通过这些地址标号最终进入到各自相应的处理程序。(init_IRQ (void)函数定义在arch/i386/kernel/IRQ.c 中;)
- interrupt[i](i从1-223),是在arch/i386/kernel/IRQ.c文件中,通过一系列嵌套的类似如 BUILD_16_IRQS(0x0)的宏,定义的一系列地址标号;(这些定义interrupt[i]的宏,全部定义在文件 arch/i386/kernel/IRQ.c和arch/i386/kernel/IRQ.H中。这些嵌套的宏的使用,原理很简单,但很烦,限于篇幅, 在此省略)
- 各以interrupt[i]为入口的代码,在进行一些简单的处理后,最后都会调用函数asmlinkage void do_IRQ(struct pt_regs regs),do_IRQ函数调用static void do_8259A_IRQ(unsigned int irq, struct pt_regs * regs) 而do_8259A_IRQ在进行必要的处理后,将调用已与此IRQ建立联系irqaction中的处理函数,以进行相应的中断处理。最后处理机将跳转到 ret_from_intr进行必要处理后,整个中断处理结束返回。(相关源码都在文件arch/i386/kernel/IRQ.c和 arch/i386/kernel/IRQ.H中。Irqaction结构参见上面的数据结构说明)
三. Bottom_half处理机制
在此版本(2.2.5)的Linux中,中断处理程序从概念上被分为上半部分(top half)和下半部分(bottom half);在中断发生时上半部分的处理过程立即执行,但是下半部分(如果有的话)却推迟执行。内核把上半部分和下半部分作为独立的函数来处理,上半部分 决定其相关的下半部分是否需要执行。必须立即执行的部分必须位于上半部分,而可以推迟的部分可能属于下半部分。
那么为什么这样划分成两个部分呢?
- 一个原因是要把中断的总延迟时间最小化。Linux内核定义了两种类型的中断,快速的和慢速的,这两者之间的一个区别是慢速中断自身还可以被中 断,而快速中断则不能。因此,当处理快速中断时,如果有其它中断到达;不管是快速中断还是慢速中断,它们都必须等待。为了尽可能快地处理这些其它的中断, 内核就需要尽可能地将处理延迟到下半部分执行。
- 另外一个原因是,当内核执行上半部分时,正在服务的这个特殊IRQ将会被可编程中断控制器禁止,于是,连接在同一个IRQ上的其它设备 就只有等到该该中断处理被处理完毕后果才能发出IRQ请求。而采用Bottom_half机制后,不需要立即处理的部分就可以放在下半部分处理,从而,加 快了处理机对外部设备的中断请求的响应速度。
- 还有一个原因就是,处理程序的下半部分还可以包含一些并非每次中断都必须处理的操作;对这些操作,内核可以在一系列设备中断之后集中处 理一次就可以了。即在这种情况下,每次都执行并非必要的操作完全是一种浪费,而采用Bottom_half机制后,可以稍稍延迟并在后来只执行一次就行 了。
由此可见,没有必要每次中断都调用下半部分;只有bh_mask 和 bh_active的对应位的与为1时,才必须执行下半部分(do_botoom_half)。所以,如果在上半部分中(也可能在其他地方)决定必须执行 对应的半部分,那么可以通过设置bh_active的对应位,来指明下半部分必须执行。当然,如果bh_active的对应位被置位,也不一定会马上执行 下半部分,因为还必须具备另外两个条件:首先是bh_mask的相应位也必须被置位,另外,就是处理的时机,如果下半部分已经标记过需要执行了,现在又再 次标记,那么内核就简单地保持这个标记;当情况允许的时候,内核就对它进行处理。如果在内核有机会运行其下半部分之前给定的设备就已经发生了100次中 断,那么内核的上半部分就运行100次,下半部分运行1次。
bh_base数组的索引是静态定义的,定时器底半处理过程的地址保存在第 0 个元素中,控制台底半处理过程的地址保存在第 1 个元素中,等等。当 bh_mask 和 bh_active 表明第 N 个底半处理过程已被安装且处于活动状态,则调度程序会调用第 N 个底半处理过程,该底半处理过程最终会处理与之相关的任务队列中的各个任务。因为调度程序从第 0 个元素开始依次检查每个底半处理过程,因此,第 0 个底半处理过程具有最高的优先级,第 31 个底半处理过程的优先级最低。
内核中的某些底半处理过程是和特定设备相关的,而其他一些则更一般一些。表二列出了内核中通用的底半处理过程。
表二、Linux 中通用的底半处理过程
| TIMER_BH(定时器) | 在每次系统的周期性定时器中断中,该底半处理过程被标记为活动状态,并用来驱动内核的定时器队列机制。 |
| CONSOLE_BH(控制台) | 该处理过程用来处理控制台消息。 |
| TQUEUE_BH(TTY 消息队列) | 该处理过程用来处理 tty 消息。 |
| NET_BH(网络) | 用于一般网络处理,作为网络层的一部分 |
| IMMEDIATE_BH(立即) | 这是一个一般性处理过程,许多设备驱动程序利用该过程对自己要在随后处理的任务进行排队。 |
当某个设备驱动程序,或内核的其他部分需要将任务排队进行处理时,它将任务添加到适当的 系统队列中(例如,添加到系统的定时器队列中),然后通知内核,表明需要进行底半处理。为了通知内核,只需将 bh_active 的相应数据位置为 1。例如,如果驱动程序在 immediate 队列中将某任务排队,并希望运行 IMMEDIATE 底半处理过程来处理排队任务,则只需将 bh_active 的第 8 位置为 1。在每个系统调用结束并返回调用进程之前,调度程序要检验 bh_active 中的每个位,如果有任何一位为 1,则相应的底半处理过程被调用。每个底半处理过程被调用时,bh_active 中的相应为被清除。bh_active 中的置位只是暂时的,在两次调用调度程序之间 bh_active 的值才有意义,如果 bh_active 中没有置位,则不需要调用任何底半处理过程。
四.中断处理全过程
由前面的分析可知,对于0-31号中断向量,被保留用来处理异常事件;0x80中断向量用来作为系统调用的总入口点;而其他中断向量,则用来处理外部设备中断;这三者的处理过程都是不一样的。
-
- 异常的处理全过程
对这0-31号中断向量,保留用来处理异常事件;操作系统提供相应的异常的处理程序,并在初 始化时把处理程序的入口等级在对应的中断向量表项中。当产生一个异常时,处理机就会自动把控制转移到相应的处理程序的入口,运行相应的处理程序,进行相应 的处理后,返回原中断处。当然,在前面已经提到,此版本(2.2.5)的Linux只提供了0-17号中断向量的处理程序。
- 中断的处理全过程
对于0-31号和0x80之外的中断向量,主要用来处理外部设备中断;在系统完成初始化后,其中断处理过程如下:
当外部设备需要处理机进行中断服务时,它就会通过中断控制器要求处理机进行中断服务。如 果 CPU 这时可以处理中断,CPU将根据中断控制器提供的中断向量号和中断描述符表(IDT)中的登记的地址信息,自动跳转到相应的interrupt[i]地 址;在进行一些简单的但必要的处理后,最后都会调用函数do_IRQ , do_IRQ函数调用 do_8259A_IRQ 而do_8259A_IRQ在进行必要的处理后,将调用已与此IRQ建立联系irqaction中的处理函数,以进行相应的中断处理。最后处理机将跳转到 ret_from_intr进行必要处理后,整个中断处理结束返回。
从数据结构入手,应该说是分析操作系统源码最常用的和最主要的方法。因为操作系统的几大功能部件,如进程管理,设备管理,内存管理等等,都可以通过对其相应的数据结构的分析来弄懂其实现机制。很好的掌握这种方法,对分析Linux内核大有裨益。
方法之四:以功能为中心,各个击破
从功能上看,整个Linux系统可看作有一下几个部分组成:
- 异常的处理全过程
-
- 进程管理机制部分;
- 内存管理机制部分;
- 文件系统部分;
- 硬件驱动部分;
- 系统调用部分等;
以功能为中心、各个击破,就是指从这五个功能入手,通过源码分析,找出Linux是怎样实现这些功能的。
在这五个功能部件中,系统调用是用户程序或操作调用核心所提供的功能的接口;也是分析 Linux内核源码几个很好的入口点之一。对于那些在dos或 Uinx、Linux下有过C编程经验的高手尤其如此。又由于系统调用相对其它功能而言,较为简单,所以,我就以它为例,希望通过对系统调用的分析,能使 读者体会到这一方法。
与系统调用相关的内容主要有:系统调用总控程序,系统调用向量表sys_call_table,以及各系统调用服务程序。下面将对此一一介绍:
-
- 保护模式下的初始化过程中,设置并初始化idt,共256个入口,服务程序均为ignore_int, 该服务程序仅打印“Unknown interruptn”。(源码参见/Arch/i386/KERNEL/head.S文件;相关内容可参见 保护模式下的初始化 部分)
- 在系统初始化完成后运行的第一个内核程序start_kernel中,通过调用 trap_init函数,把各自陷和中断服务程序的入口地址设置到 idt 表中;同时,此函数还通过调用函数set_system_gate 把系统调用总控程序的入口地址挂在中断0x80上。其中:
- start_kernel的原型为void __init start_kernel(void) ,其源码在文件 init/main.c中;
- trap_init函数的原型为void __init trap_init(void),定义在arch/i386/kernel/traps.c 中
- 函数set_system_gate同样定义在arch/i386/kernel/traps.c 中,调用原型为set_system_gate(SYSCALL_VECTOR,&system_call);
- 其中,SYSCALL_VECTOR是定义在 linux/arch/i386/kernel/irq.h中的一个常量0x80;
- 而 system_call 即为系统调用总控程序的入口地址;中断总控程序用汇编语言定义在arch/i386/kernel/entry.S中。
|